Comprehensive tutorial detailing how to install, configure, and test a processing pipeline that receives log messages from any number of syslog-ng clients, processes the incoming log messages real-time, and stores the raw filtered results into a local log directory as well as sends alerts based on thresholds being exceeded. This tutorial will also include basic abnormality detection as a demonstration of the Spark abilities.
Background
Analyzing logs and events in the modern-day is typically handled via contracts with SaaS providers that have somewhat mature and robust analytics platforms for mining information out of the forwarded events and logs. However, using SaaS providers can prove to be a headache depending on their implementation. Some providers require a central relay that all clients must forward to, and almost all require a specific agent to be installed on the client to handle the forwarding of data. These agents, while necessary, can be quite burdensome given their resource footprint.
This tutorial explains an alternative solution to both utilizing SaaS providers as well as heavyweight agents. It focuses on the second part of the streaming data pipeline and attempts to solve the issue of heavyweight agents being required for forwarding and analyzing logging data via using the lightweight syslog-ng process, which is available for almost any operating system. Specifically, this article is intended to be a comprehensive culmination of the following previously written posts/tutorials:
- Installing Kafka
- Journey to Near-Real-Time Processing
- syslog-ng Tutorial
- Integrate syslog-ng with Kafka
WARNING
This tutorial is by NO MEANS meant to convey a functional architecture that is ready for production use. It is, instead, a tutorial based on completing the requirements necessary to realize a fully functional processing pipeline. Using the details verbatim as your production processing pipeline WILL result in unexpected behavior and catastrophic failure at scale. Considerations must be made with respect to bandwidth, processing power, storage, etc. for a fully-functioning, robust, and performant production system.
Use Case
We are going to take a practical example to design towards in this tutorial. Although the example is likely very mundane and possibly not applicable in most environments given the cloud-based and other infrastructure-related DDoS and fraud detection systems, it will be a good demonstration of the capabilities that are possible with this type of data streaming stack.
Consider a scenario where there are multiple web application or REST endpoints exposed to the public internet, consumed by various other services and users. The endpoints support REST-based methods such as GET, POST, PUT, etc. Also consider that you already have a system in place that tracks/trends metrics related to the number of requests per second, including the type of request.
With the above, you have a decent understanding of the “steady state” of your system. That is to say, you likely know the typical or average number of GET requests per second, POST requests per second, etc. If, however, you were to notice an up-tick of POST requests on the order of a 20% increase over, say, 10 seconds, it is possible that you have had a surge in traffic, but if your typical requests are in the millions, a 20% increase is a huge number that is less likely to be “normal”. In these cases, you will likely want to very quickly identify such a scenario and alert someone to start looking into it (or in a more mature environment, have your software and services use such alerting information to automatically adjust and handle such cases).
The processing stack proposed below is a basic building block for the above scenario. Given a typical REST service endpoint, we can track web requests (specifically, POST requests) and alert based on whether the number of requests in a defined period exceeds a percentage increase threshold. Such an ability is critically helpful to quick resolution and defense against fraud and DDoS attacks.
Software and Service Components
The respective versions of software used in this tutorial are as follows. Other versions may work using these instructions but, as usual, your mileage may vary:
- syslog-ng: 3.7.3
- Apache ZooKeeper: 3.4.6-1569965
- Apache Kafka: 2.11-0.10.0.1
- Scala: 2.11
- Spark: 2.0.1
Underlying Compute Technology/Ecosystem
The following assumptions are made about your infrastructure. Although the instructions can be extended to accommodate cloud-based and/or other infrastructure environments quite easily, all details are explained with respect to local development for the purposes of simplicity:
- Hypervisor Technology: VirtualBox
- Provisioner: Vagrant
- Number of VMs: 4
- Operating System: Ubuntu 16.04
- Arch: 64-bit
- CPUs: 2
- Mem: 2GB
- Disk: 20GB
This tutorial is built with 4 virtual machines. The following hostnames and corresponding IP addresses will be used for the 4 virtual machine instances:
- node1.localhost: 10.11.13.15
- node2.localhost: 10.11.13.16
- node3.localhost: 10.11.13.17
- node4.localhost: 10.11.13.18
Finally, the code blocks included in this tutorial will list, as a comment, the node(s) that the commands following need to be run on. For instance, if required on all nodes, the code will include a comment like so:
# Node: node1.localhost, node2.localhost, node3.localhost, node4.localhostIf the code block only applies to one of the nodes, it will list the specific node it applies to like so:
# Node: node2.localhostAll commands assume that your user is vagrant and the user’s corresponding home directory is
/home/vagrant for the purposes of running sudo commands.
End State Architecture
At the end of this tutorial, the following end-state architecture will be realized (where “Server” is the remote instance of syslog-ng where the Client will forward logs to). Obviously in an ideal scenario the cluster-based technologies will contain a ecosystem of resources of their own, but for simplicity and resource sake, we will install it on the respective nodes as though they were their own standalone instance:
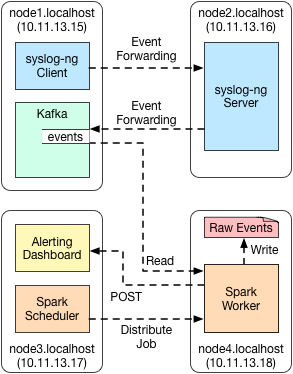
To summarize the data flow in steps/words:
- syslog-ng client on node1 sends logs to syslog-ng server (remote) on node2.
- syslog-ng server on node2 accepts logs, and forwards them to Kafka on node1.
- Kafka on node1 accepts logs, and stores them in the “events” topic locally.
- Spark job (running on node4) allocated by scheduler (running on node3) parses logs from Kafka:
- Raw POST data sent to local disk under a directory structure that includes a date and time stamp.
- Alerts (threshold exceeded events) sent via HTTP POST to the Dashboard on node3.
- Alerting dashboard on node3 updates its respective alerting mechanism to reflect an excess of POST requests over specified time interval.
Not depicted is an actual REST application - this application will run on node1 and development of the client is left as an exercise to the reader in whichever framework or technology they are comfortable in. Options such as basic Apache or Nginx servers are a possibility for quick implementation. This tutorial, however, will assume an Apache instance and utilize the access logs (out of box defaults) for parsing the respective method calls.
Additionally, the “Spark Worker” depicted on “node4.localhost” is slightly notional - this tutorial focuses on running the Spark job locally on the scheduler itself in order to view the print output for debugging purposes. It will be called out following the local run of the job what changes need to occur in order to submit the job in “cluster” mode, at which time the job could be instantiated and run from the worker node itself on “node4.localhost”.
As a note - it is likely not a great idea to simply send “alerts” in a boolean sense directly to the dashboard endpoint. This is tight coupling and limits the usefulness of the data. Instead, alternative options such as time-series databases, key/value stores, etc. should be considered. We will continue with sending data directly to the dashboard in this tutorial to demonstrate Spark’s ability to output values to external systems as well as for simplicity in design. Which architecture you choose in a more production environment is entirely dependent on both your use case and desire to have separation of concerns to help with technology abstraction (if necessary).
Technology Stack
It is REQUIRED that you follow the instructions contained in these tutorials prior to proceeding, in the order specified. Note that you must replace corresponding IP addresses and hostnames where necessary to match the detailed architecture at the start of this post:
- Install Apache ZooKeeper
- Install the ZooKeeper service on “node1.localhost” (10.11.13.15) as the architecture diagram above details.
- Install Apache Kafka
- Install the Kafka service on “node1.localhost” (10.11.13.15) as the architecture diagram above details.
- Ensure that when you create the first test topic you name it “events” if you wish to be consistent with both the architecture diagram above and the Spark application that will be developed in this tutorial.
- Integrate syslog-ng with Kafka
- Install the syslog-ng client on “node1.localhost” (10.11.13.15) and the syslog-ng server on “node2.localhost” (10.11.13.16) as the architecture diagram above details.
- Ignore the “Kafka” section in this linked article as you can simply re-use what you performed in step 2 above to install Apache Kafka on “node1.localhost”.
- You will likely need to update the “client” (node1.localhost) syslog-ng configuration to point to a local Apache or other access log file for the Spark application to function as expected.
The steps following this section assume that you have followed these previous tutorials and have a fully-functioning syslog-ng ecosystem forwarding logs to the Kafka instance. Failure to first perform this listed tutorial will result in a non-functioning technology stack.
Install and Configure Spark
This next part to install and configure Spark is a repeat of a previous post here. The steps will be repeated below for consistency and to ensure accuracy with the environment in which the technology is now installed, and the Master and Worker nodes are slightly different.
As a prerequisite, you need to install the Java dependencies if not already installed:
# Node: node3.localhost, node4.localhost
$ sudo apt-get install default-jre default-jdkEnsure that all 4 hostnames are resolvable between the various hosts - this can be as simple as
adding a line to the /etc/hosts file on each node to ensure hostname resolution is possible.
Next, download and extract the required package:
# Node: node3.localhost, node4.localhost
$ cd ~
$ wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.1-bin-hadoop2.7.tgz
$ tar xzf spark-2.0.1-bin-hadoop2.7.tgz
$ cd spark-2.0.1-bin-hadoop2.7/Create a logging directory for the Spark process:
# Node: node3.localhost, node4.localhost
$ sudo mkdir /var/log/sparkSet some configurations for the Spark processes - note that some memory tuning is done in order to ensure that jobs do not over-commit the small amount of VM resources, but the memory specified in these configurations are way too low for any kind of complicated processing:
# Node: node3.localhost, node4.localhost
$ cp conf/spark-defaults.conf.template conf/spark-defaults.conf
$ vim conf/spark-defaults.conf
# add the following configuration directives to the end of the file:
# spark.driver.memory=512m
# spark.executor.memory=512m
# spark.executor.cores=1
# Node: node3.localhost, node4.localhost
$ cp conf/spark-env.sh.template conf/spark-env.sh
$ chmod 775 conf/spark-env.sh
# Node: node3.localhost
$ vim conf/spark-env.sh
# add the following configuration directives to the end of the file:
# SPARK_MASTER_HOST=10.11.13.17
# SPARK_LOG_DIR=/var/log/spark
# Node: node4.localhost
$ vim conf/spark-env.sh
# add the following configuration directives to the end of the file:
# SPARK_LOCAL_IP=10.11.13.18
# SPARK_LOG_DIR=/var/log/sparkOnce the above configuration files are in place, you can start the Spark processes. Ensure that the processes are started in this order to ensure that the worker can connect to the master instance:
# Node: node2.localhost
$ sudo /home/vagrant/spark-2.0.1-bin-hadoop2.7/sbin/start-master.sh
# you should see some output along the lines of:
# starting org.apache.spark.deploy.master.Master, logging to /var/log/spark/spark-root-org.apache.spark.deploy.master.Master-1-node3.out
# Node: node3.localhost
$ sudo /home/vagrant/spark-2.0.1-bin-hadoop2.7/sbin/start-slave.sh spark://10.11.13.16:7077
# you should see some output along the lines of:
# starting org.apache.spark.deploy.worker.Worker, logging to /var/log/spark/spark-root-org.apache.spark.deploy.worker.Worker-1-node4.outOnce you have performed the above, you can follow the steps under the “Apache Spark -> Validation” section in the original post here if you wish to validate your installation. Remember to replace all hostnames and IP addresses in the validation section with the respective hostnames/IP addresses of the hosts in this specific tutorial.
Spark Streaming - Abnormality Detection
Now that we have a fully-functioning ecosystem, we can develop the Spark Streaming application. We will expand on the steps detailed here to develop and schedule a Spark application that parses events for POST requests made of a REST endpoint to determine if the number of POST requests has increased more than 20 percent for the last 10 seconds as compared to the previous 10 second batch. The example is being kept simple in terms of hard-coded values but in reality, this would likely be a somewhat useless functionality without trending-based adjustments to the threshold limits (which are a bit more advanced than needed for this tutorial).
Application Development
To get started, first create the directory structure required for the application on “node3.localhost”:
# Node: node3.localhost
$ cd ~
$ mkdir TestApp
$ cd TestApp/
$ mkdir -p lib \
project \
src/main/scalaNext, construct the assembly.sbt file to specify we wish to create an “uber jar” (packaged with
most of the required dependencies to avoid having to specify classpath and/or send libs to
the executor when the application is started):
# Node: node3.localhost
$ vim project/assembly.sbt
# ensure contains the following:
# addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.2")Once you have configured the environment for the assembly plugin, construct the Scala build tool
project metadata file as follows. Place the following code contents into the file
/home/vagrant/TestApp/build.sbt on “node3.localhost”:
name := "TestApp"
version := "0.0.1"
scalaVersion := "2.11.6"
libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "2.0.1" % "provided"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.0.1" % "provided"
libraryDependencies += "org.apache.spark" % "spark-streaming-kafka-0-10_2.11" % "2.0.1"
libraryDependencies += "org.scalaj" % "scalaj-http_2.11" % "2.3.0"
// override any 'deduplicate' strategy with a 'pick last to avoid errors'
assemblyMergeStrategy in assembly := {
case PathList("META-INF", "MANIFEST.MF") => MergeStrategy.discard
case x => MergeStrategy.last
}Next, construct the application code. Details about code functionality are included as comments
within the code blocks themselves. Note again that this code is VERY fragile in the sense that
boundary-condition checking is minimal and efficiency is non-optimal - it is intended to be
a VERY basic starting point for this tutorial alone. Place the following code contents inside
the file /home/vagrant/TestApp/src/main/scala/TestApp.scala on “node3.localhost”
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.{StreamingContext, Seconds}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import java.util.Calendar
import java.util.concurrent.atomic.AtomicLong
import java.text.SimpleDateFormat
import scalaj.http.{Http, HttpOptions}
object TestApp {
// define some values for intervals, previous data storage,
// and a regex pattern for POST request matching
// counts for comparison
val BATCH_INT = Seconds(10)
val POST_PATTERN = "POST".r
val THRESHOLD = 20.0
val previousCount = new AtomicLong(0)
def main(args: Array[String]) {
// handle the input arguments
if (args.length < 2) {
System.err.println("Usage: TestApp <brokerInstances> <topicName> <alertURL>")
System.exit(1)
}
val Array(brokerInstances, topicName, alertURL) = args
// create a configuration and new Spark, SQL, and Streaming context
val sparkConf = new SparkConf().setAppName("Abnormality Detection")
val ssc = new StreamingContext(sparkConf, BATCH_INT)
// set up the configuration for the stream processing from Kafka data
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> brokerInstances,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "POSTAnomalyDetect",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// create the Direct Stream integration for processing
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](Array(topicName), kafkaParams)
)
// calculate (rough) whether there is an abnormal increase in total
// POST requests based on %change between previous/current counts
// Note: There will only ever be a single RDD based on usage of a
// single batch interval without any window operation, so calculating
// this way is "safe enough"
// also note that although filtering of POST messages are included,
// if any run includes data that has NO POST messages, this code will fail
stream.foreachRDD { rdd =>
var stamp = Calendar.getInstance().getTime()
val date = new SimpleDateFormat("y-M-d").format(stamp)
val time = new SimpleDateFormat("HmsS").format(stamp)
val filePath = "/tmp/logs/" + date + "/raw/" + time + "/"
var postOpCount = 0L
var change = 0.00
if (rdd.count() > 0) {
// capture all POST operations in batch - note that the regex-based matching
// in this method is likely unsafe and it would be better to transform the
// web logs/events to key/value pairs and operate on request type explicitly,
// but for simplicity this will work, and opening/creating Kafka connections
// without using partitions in this case will also suffice (although
// definitely not best practice)
println("Capturing POST operations...\n")
val postOps = rdd.filter(event => POST_PATTERN.findFirstIn(event.value).isDefined)
postOpCount = postOps.count()
println(postOpCount + " POST operations captured.\n")
// write the raw POST records to a file
println("Writing raw POST data to file...\n")
postOps.saveAsTextFile(filePath)
println("Raw data written to: " + filePath + "\n")
// compare current batch to previous batch for rate of change
println("Calculating % change from previous batch...\n")
change = ((postOpCount.toFloat - previousCount.get().toFloat) / postOpCount.toFloat) * 100
} else {
// determine if we've gone from something to nothing, or stayed stable
// at 0 records between batches (0% change)
println("No records in RDD\n")
if (previousCount.get() > 0) {
change = -100.00
}
}
// keep track of current for next batch interval, and output change result
println("% change calculated: " + change + " | (PREV: " + previousCount.get() + " | CUR: " + postOpCount + ")\n")
previousCount.set(postOpCount)
// check if change rate exceeded threshold and, if so, alert/send data to Dashboard
if (scala.math.abs(change) > THRESHOLD) {
println("Threshold exceeded - sending alert to Dashboard...\n")
// publish the change rate result to the dashboard
// NOTE: This is NOT exception-safe - if the dashboard is down, bad
// things may happen
val result = Http(alertURL).postData("""{ "auth_token": "YOUR_AUTH_TOKEN", "items": [{"label": "Change Rate Exceeded - CURVAL:", "value":""" + change + """ }]}""")
.header("Content-Type", "application/json")
.header("Charset", "UTF-8")
.option(HttpOptions.readTimeout(3000)).asString
println("Alert sent to Dashboard successfully.\n")
}
}
// take action based on the above configurations
ssc.start()
ssc.awaitTermination()
}
}Once you have created the directory structure and respective application files/code, run the sbt
command to assemble your “uber” jar:
# Node: node3.localhost
$ sbt assembly
# should see a bit of output, something along the lines of:
# [info] Loading project definition from /home/vagrant/TestApp/project
# [info] Set current project to TestApp (in build file:/home/vagrant/TestApp/)
# [info] Updating {file:/home/vagrant/TestApp/}testapp...
# [info] Resolving jline#jline;2.12.1 ...
# [info] Done updating.
# [info] Compiling 1 Scala source to /home/vagrant/TestApp/target/scala-2.11/classes...
# ...
# [warn] Strategy 'discard' was applied to a file
# [warn] Strategy 'last' was applied to 8 files
# [info] SHA-1: b5e20b9ea3892f21c81e670f269a94023fe4b976
# [info] Packaging /home/vagrant/TestApp/target/scala-2.11/TestApp-assembly-0.0.1.jar ...
# [info] Done packaging.
# [success] Total time: 16 s, completed Dec 27, 2016 11:15:33 PMIf the [success] line shows up at the bottom of the output generated, your uber jar has been
successfully assembled and is ready for use.
Dashboard - Install and Create View
Let’s get the Dashing dashboard installed and configured - we will be using the Dashing dashboard framework. This tool is outdated and no longer in active development, but is robust enough to get a very simple dashboard up and running very quickly. To help with staying more current, we will install the forked/maintained version of the dashboard Smashing.
The steps that follow are all implemented on “node3.localhost”. Therefore, the notes about which node to run the commands on are omitted for brevity.
Installation
To install Smashing, the system requires Ruby and bundler to be installed. Recommended is to use the RVM version management system - instructions can be found via the link provided.
Once Ruby and bundler are installed, we can get started installing the Smashing framework by following the instructions in the README here. One note - there is a well documented issue here regarding using the Thin framework for serving the dashboard (dashboard will not update/will apear to hang when using Thin on certain operating systems and browser combinations). These instructions include installing and using Puma to serve the dashboard in order to address this issue:
$ cd ~
$ gem install smashing
$ smashing new stream_alert
$ cd stream_alert/
$ vim Gemfile
# to accommodate AJAX functionality, we need a JavaScript
# execution engine - we will use the most common:
$ sudo apt-get install nodejs
# also need to install puma to avoid "not updating" issue
$ vim Gemfile
# add the following line:
# gem 'puma'
$ bundle install
$ puma config.ruOnce the above has been completed, you should have a fully functioning Smashing dashboard. Open a browser window and navigate to http://10.11.13.17:9292 - if all is successful, you should see a Smashing example dashboard with example widgets that are updated approximately every 2 seconds.
Custom Dashboard Creation
Now that our Smashing framework is up and running, we can get started with creating our own custom
dashboard. Place the following HTML contents into the file /home/vagrant/stream_alert/dashboards/stream.erb
on “node3.localhost”:
<% content_for :title do %>Stream Alerting<% end %>
<div class="gridster">
<ul>
<li data-row="1" data-col="1" data-sizex="4" data-sizey="1">
<div data-id="alerts" data-view="List" data-unordered="true" data-title="Alerts" data-moreinfo="Alerts from the streaming platform"></div>
</li>
</ul>
</div>Since we will be using the POST method of communication from Spark to the dashboard directly (again, this is certainly not preferred, but simple for this tutorial), there are no jobs to configure in the Smashing framework. Let’s go ahead and start our Smashing dashboard server - if it is still running from the setup instructions above, kill it and restart it:
$ puma config.ruNext, visit our new dashboard by navigating to http://10.11.13.17:9292/stream. There should be a
single widget with the title “Alerts” on the page with no data.
End to End Test
Now, let’s launch the created application. Doing so in this fashion ensures that you will see the
println output statements but is definitely not the way you would want to deploy your application
in a production-like environment (for prod-like environments, use of “cluster” deployment mode is
much preferred). The deployment of the application will be done from a separate SSH terminal connected
to the “node3.localhost” instance:
# Node: node3.localhost
$ cd /home/vagrant/TestApp
$ SPARK_LOCAL_IP=10.11.13.17 ../spark-2.0.1-bin-hadoop2.7/bin/spark-submit \
--driver-memory 512m \
--master local[2] \
/home/vagrant/TestApp/target/scala-2.11/TestApp-assembly-0.0.1.jar 10.11.13.15:9092 events http://10.11.13.17:9292/widgets/alerts
# should see lines of output scrolling...Note: The above command runs the Spark job locally on the Spark Scheduler node. If you wish to
submit the job to utilize cluster resources (i.e. run the job on “node4.localhost” in background
mode, which is the preferred operation for a more production-like approach), simply add the switch
--deploy-mode cluster and update the --master parameter to read as spark://10.11.13.17:7077.
You will likely also wish to use the --executor-memory and --total-executor-cores parameters
to define the resource constraints for the job since the virtual machines are not very bulky
instances. Submitting the job in cluster mode, however, will prevent you from easily viewing the
print output embedded in the job itself without going through the web interface, so you are
encouraged to submit locally in a more debug fashion to assist with any troubleshooting that may
need to occur.
Now that you have your full processing pipeline in place, it’s time to generate some data to
test the functionality of the system. This exercise is left up to the reader, but in the case
of this tutorial where an Apache instance with access logs is used, simply performing POST
requests against the root URL of the “node1.localhost” web application and varying the number
of requests drastically (more than 20%) should suffice. In doing so, you will see the percent
increase show up in the Kafka alerts topic as well as the following output in the Spark job:
Capturing POST operations...
...
12 POST operations captured.
...
Writing raw POST data to file...
...
Raw data written to: /tmp/logs/2016-12-27/raw/2155407/
...
Calculating % change from previous batch...
...
% change calculated: 33.33 | (PREV: 8 | CUR: 12)
...
Threshold exceeded - sending alert to Dashboard...
...
Alert sent to Dashboard successfully.
Once the above has triggered, inspect your dashboard in the browser (http://10.11.13.17:9292/stream).
You should see the “Alerts” table populated with some data corresponding to alerts of exceeded
thresholds.
As a note, the very first time you start the application and send data, it is likely you will see an alert show up in the Alerts list of the dashboard due to the fact that when you start sending data while the system is running, any data is more than the 0 data the system was previously receiving. You can either ignore this, or if you wish to get a more concise test, you can start your steady-state generation of POST requests prior to starting the Spark application, which should ensure the application calculates a very small (or no) percent change from time zero.
In addition to the alerting, you should be able to inspect the log directory on “node3.localhost” (where the Spark application is running) for the raw output of POST messages. This is useful for post-processing or inspection during events, or can be used to re-play messages for future learning or anomaly detection:
# Node: node3.localhost
$ ls /tmp/logs/
# 2016-12-30
$ ls /tmp/logs/2016-12-27/
# raw
$ ls /tmp/logs/2016-12-27/raw/
# 2155407
$ ls /tmp/logs/2016-12-27/raw/2155407
# part-00000 _SUCCESS
# inspection of part-0000 will show you the POST messages captured during
# the date/time specified in the directory structureSummary
If you’ve completed this tutorial, you now have a fully-functional stream processing architecture in place. There are SEVERE limitations and risks involved with this particular framework that have been called out within the article itself. In addition, there are many enhancements that should likely be made to ensure this processing pipeline and its associated visualization and storage mechanisms make sense for the business requirements of the task you wish to accomplish.
However, with all disclaimers and warnings aside, this document details the starting point to understanding and building out a cohesive stream-processing framework for high-volume data ingest and processing that can be applied to many subject areas. If you have successfully built this architecture and the end-to-end testing proved successful, you are on your way to understanding “big data” as it relates to the technology that facilitates processing such information. Be forewarned, however, that this is just the absolute tip of the iceberg as it relates to this subject area - many engineers have spent entire careers attempting to understand these concepts and perfect the principles behind them, so do not get discouraged if it takes a long time to pick up the concepts and topics within.
Credit
The above tutorial was pieced together with some information from the following sites/resources: