Techstream
-

Concourse on k8s
Concourse is a fantastic orchestration component that can be used in a very pluggable/flexible way. This tutorial lays the groundwork for the use and exploration of Concourse by installing it on a k8s cluster. The expectation is that this install can be used to explore Concourse functionality as it relates to the various GitOps-like flows and k8s technologies available for software delivery and general administration.
-

k8s GitOps with FluxCD
GitOps is a highly valuable concept for deploying and maintaining software using machines. This tutorial builds on this previous tutorial by using flux to monitor the example tiny busybox web server in this repository for changes (commits, merges, etc.), and automatically deploys/updates the running instance in the k8s cluster running from this previoustutorial (although any k8s environment should suffice).
-

-

Vagrant k8s Cluster
This post details a different way to experiment with a Kubernetes cluster that is a bit more advanced and powerful than utilizing minikube on your local workstation. The tutorial walks you through setting up a Kubernetes cluster on a suite of VMs hosted on your workstation using VirtualBox and Vagrant, with Ansible for configuration management of the cluster nodes (to transform them into their identities and form the cluster).
-

k8s Cluster Usage
Expanding on this previous post, this post details some basic fundamentals of Kubernetes (k8s) and its purpose. It is intended to be some quick high-level summaries of many core functions and some quick hits for interacting with and managing workloads on k8s.
-

Configuring Traefik as k8s Ingress Controller
Kubernetes (k8s) clusters can have LoadBalancer-type services expose deployments over a specific IP and port to the outside world. However, as the Service object works at Layer 4 of the OSI model, this can fast become very expensive as each Service would end up with its own LoadBalancer with specific IP and port. In addition, this implementation requires a dedicated Load Balancer that can support API interaction for configuring the instance. This post details how to set up an Traefik Ingress controller and load balancer that supports OSI Layer 7-based load distribution, allowing re-use of a dedicated IP address and dynamic path-based routing to back-end services.
-

Raspberry Pi k8s Cluster
Kubernetes (k8s) is a container orchestration platform that’s transforming the way software services are deployed and managed. For less than the cost of production-grade infrastructure, one can purchase multiple Raspberry Pi boards, network them together, and create a fully functioning k8s cluster for personal development and experimentation. This post details how to put together 3x Raspberry Pi 3 B+ hardware boards, link them on a private network, and install a fully functioning k8s cluster for personal use and experimentation.
-

SSH Agent Hijacking
Use of SSH Agent Forwarding is a common way to enable re-using SSH keys from a source and jumping through multiple hosts over SSH. However, this method comes with a potential risk of hijacking where compromise could mean a malicious actor using the SSH keys to access downstream hosts without the user knowing. This quick tutorial demonstrates how SSH hijacking can occur.
-
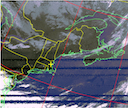
Acquiring NOAA Weather Satellite Imagery using SDR
In a completely different direction from previous posts, this post will detail some initial findings in exploring the world of Software Defined Radio (SDR), which has been around for quite some time. This post details initially setting up an antenna, SDR, and software to receive Automatic Picture Transmission (APT) signals from the National Oceanic and Atmospheric Administration (NOAA) satellites which offer transmission of weather imagery from space.
-

MySQL Snapshots Using ZFS
This post is an expansion on this previous post detailing basic usage of the Z File System. This post expands on the Z File System example and provides snapshot and rollback capability for a MySQL Database. By the end of this post, you will have a fully installed/functioning MySQL database with snapshot/rollback capability like a time machine for your data. This functionality can further expand your CI use cases by providing a refresh capability that is much faster than continuously seeding a database with data on each test run.
-

Snapshot Rollbacks with ZFS
In creating a CI pipeline, often times the data layer/availability is the trickiest to handle regarding preparing for tests. Seeding a database with the right data for starting tests and refreshing it when new/other tests are run is cumbersome and often times requires customized scripts with long wait times for schema drop and data injection. There are a few data virtualization technologies out there today (i.e. Delphix, etc.). If you’re looking to just experiment with what a data virtualization technology could afford you, a good place to start is to take your already existing customized scripts for seeding/re-injecting data and modifying them to use the Z file system with its snapshot capability. This tutorial attempts to explain some basic concepts behind ZFS using standard file create/rollback using snapshots, which could further be expanded to database functionality.
-

Parallelized Jenkins Jobs using Docker
As software test suites grow, so does the timeline for feedback to a developer given the length of time it takes to run the tests. In a monolithic environment this problem can be compounded if the suite of tests is singular and inclusive of all functionality. This post is an attempt to solve this problem using Docker containers with parallel test jobs.
-

CI/CD Pipeline for Infrastructure VMs
In a traditional IT/Operations department, there is often slow feedback in delivering updated VM templates that are hardened and tuned (with possibly platform components installed), so by the time someone discovers there is a zero-day vulnerability or memory leak in a platform software component, there is a day(s) (sometimes weeks) long process to roll out new infrastructure or patch existing. This post details a sample CI/CD pipeline and process that enables security, infrastructure and platform teams to manage the templates used for software deployments in a software-like delivery method (infrastructure as code, CI process with smoke testing and fast feedback, etc). The tutorial attempts to establish a governance and feedback process to arrive at AWS AMI-like functionality where an automated pipeline, along with Ansible scripts and other code, produces new VM templates that can be consumed by an organization, providing fast feedback to infrastructure, security, and platform teams if and when a change ends up breaking downstream VM template components.
-

ESP8266 Temperature Sensor
This post is an attempt to detail how to use (and program) an ESP8266 wifi board with a DHT22 temperature/humidity sensor to send data to an endpoint running Graphite and Statsd for routine metric collection of temperature and humidity data. It builds on this previous post which configures a Raspberry Pi 3 B+ as a central Graphite, Statsd, and Grafana endpoint and forms the basis of a wireless, cheap sensor network.
-

Raspberry Pi RX/TX with XBee Devices
Experimenting with electronics (and somewhat re-learning much of what I’ve forgotten since college), this post details how to utilize Raspberry Pi controllers to communicate with each other wirelessly using XBee Series 1 modules. The learnings and circuit/communication methods lay the groundwork for more complicated robotics remote control capabilities.
-

ELK Stack Install
This is a quick refresher on installing and configuring an ELK stack in an Ubuntu multi-VM cluster. For simplicity, we’ll use Ansible to configure the target instances and the Ansible code can be found in my Scriptbox Github project here. In addition, instead of installing Logstash, we will install the Filebeat capability.
-

Kubernetes Part 9: ConfigMaps
Now that we have core components ironed out, let’s talk about configuration. We somewhat jumped ahead in our previous post about Secrets before we addressed configuration strategy, so we will revisit the configuration topic in this post with the use of ConfigMap objects.
-

Kubernetes Part 8: Persistent Volumes
Up to this point, any storage utilized by Pods will disappear if and when the Pod/Container is destroyed. This is acceptable for stateless applications but less desirable for stateful applications and databases. This post will go over how to create and use a Persistent Volume across multiple Pods to demonstrate how to create stateful application deployments.
-

Kubernetes Part 7: Secrets
Previously we created an application and hard-coded the password for accessing the database (bad). In this tutorial, we will learn about Kubernetes Secrets and how to use them to store sensitive information in a safer way.
-
Kubernetes Part 6: Rolling Updates
Now that we have a running application hooked up to a database, we will explore how to go about rolling updates (zero-downtime updates) of the application.
subscribe via RSS